


Measuring the Rate of War Outbreaks

Introduction
In 1944, Lewis Fry Richardson reported that the number of wars that began (or ended) each year closely resembled a Poisson distribution. From this, Richardson speculated that there was a ‘persistent background of probability’ for the start and end of wars.
This hypothesis that wars randomly occurred at a constant rate throughout history discouraged some International Relations researchers from investigating causes and consequences of the occurrence of war: “meaningful causal research […] would come to a standstill because of the lack of variation in substantive variables”.1
Thirty years ago I vehemently disagreed:2
Both systematic and stochastic regularities deserve scientific attention. If exactly one war occurred each year, would this lack of variation render causal research on the pattern of war outbreaks futile? On the contrary, wouldn’t such precise regularity demand causal explanation? A simple Poisson process, despite its additional stochastic component, is just as precisely regular […] If we could account for the distribution of war outbreaks over the past several hundred years using a simple Poisson process, this would be a fascinating result. What mechanisms could guarantee the same rate of war outbreak, despite the vast changes in population, mobility, weapons, governments, etc., that have taken place throughout this time period?
However it turns out that the rate at which wars have broken out has not been constant. We can measure that rate and see how it has changed historically.
If you find the mathematical model that follows difficult to digest, skip ahead to the google spreadsheet that you can play around with. Then you can return to the formulas and they’ll start to make sense.
Mathematical model: the random hazard doubly stochastic Poisson process
Despite the lengthy moniker, this is pretty much the simplest model that permits the rate at which events occur to vary: two fixed rates at which events occur and a constant rate of switching between those rates. This is clearly an oversimplification — it’s not what really happened — but it’s still a useful tool.
Notation:

Statistical inference: recursive Bayesian estimation
In recursive Bayesian estimation, we repeatedly apply the following two steps to the probability distribution that represents our inference about an unobservable state (in this case, whether the event rate is High or Low) of a dynamic process:
Apply the system dynamic (in this case, a Markov chain) to our previous posterior estimate to get our current prior estimate.
Update this prior with the current observation (i.e., apply Bayes’ Rule) to produce our current posterior estimate.
Prior Distribution (maximum entropy initial condition):
System Dynamic Model(s):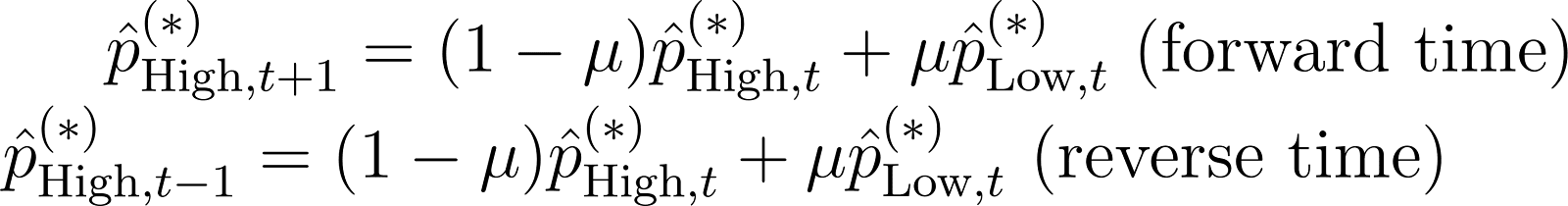
Measurement Model (Bayes' Rule):
Log likelihood (of model parameters):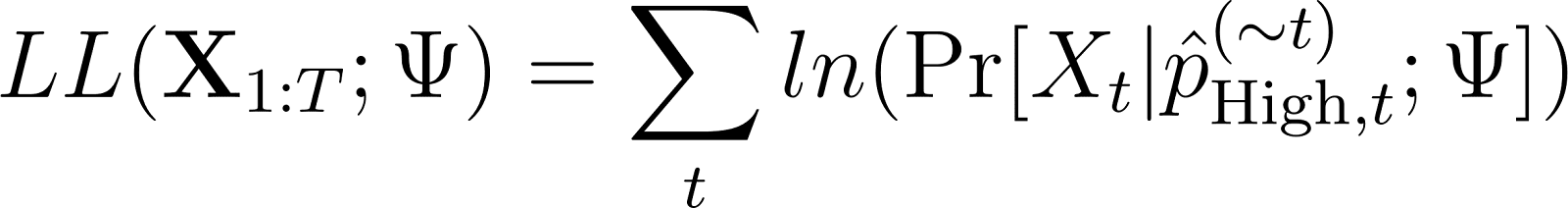
Estimate the model parameters by finding values that maximize the log likelihood.
Spreadsheet implementation
I have implemented the model as a Google sheet. To play around with it, make a copy for yourself.
The sheet has two tabs:
Estimate tab
This tab holds the model parameters (A1:C4), Poisson distribution table (A6:C16) for both the Low and High event rates, log likelihood (A18:B18) and a couple of charts (see the Discussion section below).
Data tab
This tab holds data I obtained from the Correlates of War Project.3
The ‘raw’ data appears in the first three columns (I actually had to count the number of wars occurring in each year in order to populate the tab).
Columns D & E hold the Observation probabilities, looked up from the Estimate tab’s Poisson distribution table.
Columns F & G run the recursive Bayes estimate forward in time. Column F contains the forward prior probability that the rate (of war outbreak) is high for the current year; that is, the probability that the rate is high given what’s taken place in all of the previous years. Set the initial value (F3) using our prior distribution, which assumes that the high and low rates are equally likely. Column G computes the forward posterior by applying Bayes’ Rule to the forward prior conditioning on the actual number of war outbreaks that year.
Columns H & I run the recursive Bayes estimate backwards in time, computing the reverse prior (H) and reverse posterior (I).
Column J combines the forward and reverse priors into a jackknife4 prior. Column K holds the log likelihood of what happened that year given our parameter values applied to all of the other data. Column L is the expected value of the rate of war outbreak based on the jackknife prior.
Columns M & N contain ‘smooth’ (also referred to as ‘smoothed’, ‘complete’ or ‘full’) estimates that use all of the data (in particular, including the number of war outbreaks in the current year). Column M is the smooth posterior probability that the rate is high: apply Bayes’ rule to the jackknife prior using this year’s number of war outbreaks. Column N is the corresponding expected value of war outbreak rate.
Discussion
I summed Data tab column K to get the log likelihood (Estimate tab A18). I then used the Solver extension to estimate the maximum likelihood model parameters. We obtain rate estimates of 1.3 outbreaks/year (low) and 2.4 outbreaks/year (high), implying that there have been some historical eras in which wars were nearly twice as likely to begin as in other historical eras. This is a pretty large departure from a constant rate for all of history.
The estimated transition rate between the high and low outbreak rates is 0.03; that is, on average, each ‘era’ lasts about 33 years. See my dissertation (footnote #2) for discussion of the correspondence to ‘long cycles’ in the international system.
The ‘Expected Rate of War Outbreak’ chart (Estimate tab) displays our smooth estimate over the historical period. Notice that even though our model assumes just two rates, the estimated rate varies continuously (‘smoothly’!). We see low estimates in the first half of the 19th century and between the two World Wars; there’s also a dip in the last half of the 19th century.
How well does the model perform? One way to assess performance is to see how well the jackknife estimates ‘predict’5 what actually happened; see the ‘Actual Vs. (Jackknife) Prediction’ chart. When the predicted rate is low, there tend to be fewer outbreaks; similarly when the prediction is high, there tend to be more. However, a couple of the years with the highest number of outbreaks occurred when the predicted rate was intermediate.
Linear regression is one way we can summarize predictive accuracy. With perfect prediction, the linear regression slope would be exactly one. In the chart, we see that the slope is 0.76, which is pretty good: a lot closer to one than zero.6
Generality
Notice that this model can be applied to any event process such as goal scoring in hockey or soccer, “factory accidents, deaths by kick from a horse, and the emission of alpha particles from radio-active substances”7.
Ideas for improvement
Apply the model to shorter (or longer) time intervals; I plan to explore this in a future post.
A different transition rate from High to Low event rates vs. Low to High.
More event rates; continuously variable event rates.
Non-trivial system dynamics. For example, when there are a lot of ongoing wars does this suppress the outbreak of additional wars? Or, say, do lengthy peaceful eras cause rulers to forget the horrors of war?
Develop additional diagnostics for the model’s performance (also a future topic for this newsletter).
I use the Auto-Latex Equations add-on in Google Docs to render my math formulas. Could someone show me how to (1) align the equations (it seems like the add-on can’t use packages); (2) specify the font size?
Houweling, H.W. and J.B. Kuné (1984) “Do Outbreaks of War Follow a Poisson-Process,” J. of Conflict Resolution 28(1):51-61.
Pudaite, Paul R. (1991) Explicit mathematical models for behavioral science theories, page 66.
The Project has updated the dataset since I uploaded the data in my Google Sheet. Feel free to extend my sheet to incorporate the additional data!
I put predict in scare quotes because the jackknife includes data obtained afterwards; it does exclude the current year’s observation. But there’s still a tiny bit of ‘cheating’ because the parameter estimates are slightly influenced by the current year. This influence can be eliminated by excluding the current year when estimating the parameters. It’s too cumbersome to do this with Google Sheets, but it’s tractable if you write a computer program.